Introduction:
Prior to vSphere 6.5, Windows Failover Cluster and Fault Tolerance (after it was improved to support 4 vCPU in vSphere 6.0) were two applicable methods to protect vCenter. These didn’t provide a real HA for vCenter as FT is not application-aware and WFC is good for windows vCenter but not for VCSA appliance. Starting from vSphere 6.5, VMware provides VC HA cluster as a native feature with vCenter appliance to protect VCSA.
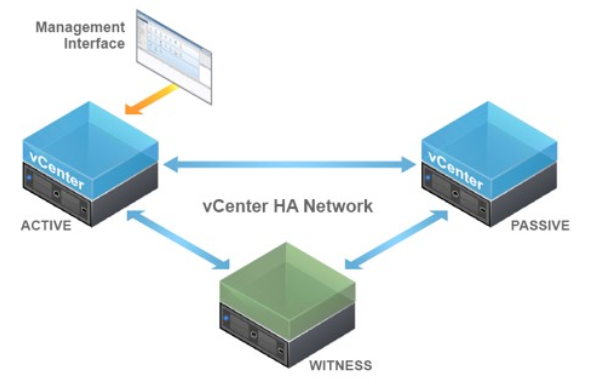
The vCenter High Availability architecture uses a three-node cluster to provide availability against multiple types of hardware and software failures. A vCenter HA cluster consists of one Active node that serves client requests, one Passive node to take the role of Active node in the event of failure, and one quorum node called the Witness node.
Issue:
In a recent customer engagement, and as I prepared all ESXi hosts and installed VCSA vCenter server (version 6.5 Update d”) and configured VDS switches and distributed portgoups, I then decided to configure VCHA cluster to protect my vCenter.
I completed the basic wizard and the deployment started normally cloning a copy of the current VCSA for the peer node until it get stucked at 44%.
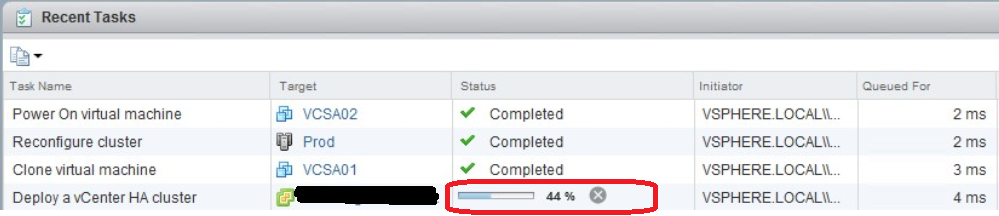
The below error message appeared:
“A general system error occurred: Failed to ssh connect peer node x.y.z.w”.
Although I was sure that SSH is enabled on vCenter prior to VCHA configurtion, after the clone is done for the peer node, the active node failed to SSH to the peer node for some reason causing the task to hang on 44%.
I tried to restart vCenter appliance but it seemed that VCSA is not working anymore after VCHA cluster configuration has been failed. If you logon to the appliance via direct console, you can see that all services are down and the node has entered an isolation mode.
Solution:
It was a network issue. The private HA network that is used for VCHA cluster nodes heart beat communication was created on the physical switches and a portgroup was created however that VLAN was not allowed on the trunk interface of the ESXi traffic. This means no communication between vCenter HA nodes can occure via HA network.
As we specified to install VCHA nodes on different ESXi hosts during the basic configuration wizard, and as VCHA uses the HA network to SSH to peer node during installation, it will fail causing the active VCSA node to enter an isolated mode.
We fixed the network issue. However, our vCenter is down and we want it back…
The solution to this is to recover from isolated vCenter HA nodes by destroying VCHA cluster and attempting to re-create the VCHA cluster after the network issue was solved. The below steps show how you can recover from isolated vCenter HA nodes:
- Power off and delete the Passive and Witness nodes.
- Log in to the Active node by using SSH or via Direct Console.
- Log in as the root user and enable the Bash shell: # shell
- Run the following command to remove the vCenter HA configuration: # destroy-vcha -f
- Reboot the Active node: # reboot
- Wait until the Active node is back online.
The Active node will become a standalone vCenter Server Appliance. You can now start vCenter HA cluster configuration again.
Mohamad Alhussein


 (3 votes, average: 3.67 out of 5)
(3 votes, average: 3.67 out of 5)
What exactly was the networking issue you faced? We are seeing similar and can’t seem to pinpoint it. We’re able to ping the passive node and witness node but can’t ssh. Been through basic and advanced install to no avail.
Hi Alex,
The network issue I faced was that the internal HA network used for heartbeating between the peer, passive and witness node, was not allowed on the trunk uplink interfaces of the three ESXi nodes where these VCHA cluster nodes reside. Thus the active peer was unable to ssh the passive node on the other ESXi node.
Let me know something please, SSH needs to be enabled on the first VCSA node before intiating the creatin of the VCHA cluster, did you do so ?
Please let me know if your problem is solved or you need any further help.
I’m having the same problem… Not sure what needs to be changed to allow the access on the trunk uplink interfaces.
Hi Trevor,
As the 3 vCenter nodes can reside on different ESXi hosts, they need to communicate with each other through the HA network, so although the HA network should be internal to these nodes, it should be allowed on the trunk uplink interfaces of the ESXi hosts. All what you need to do is to allow the HA network VLAN on that switch trunk interfaces connected to the ESXi hosts.
Hope this helps you resolve your issue,
It was 44% where my job was stalling/failing as well.
“Deploy a vCenter HA cluster Status:A general system error occurred: Failed to ssh connect peer node…”
I had incorrectly placed the Active node on a not-yet-used vDS port group which had a name similar to the port group I had created on my 3 standard switches across my 3 hosts. I spotted that when I re-ran the setup after destroying previous attempt and deleting the Passive instance.
So I corrected the Active node, setting it to the port group I had created on my 3 standard switches, during setup, only to see the same failure.
I then checked Edit Settings on my Active node and found the new heartbeat vNIC was still plugged into the wrong port group. Fixed it in here and rinsed/repeated and all is well now.
Version
6.7.0
Build
14368073