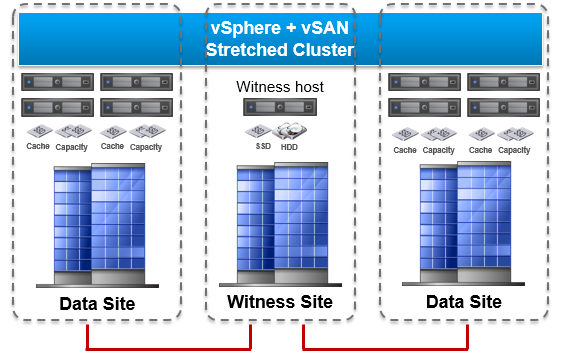
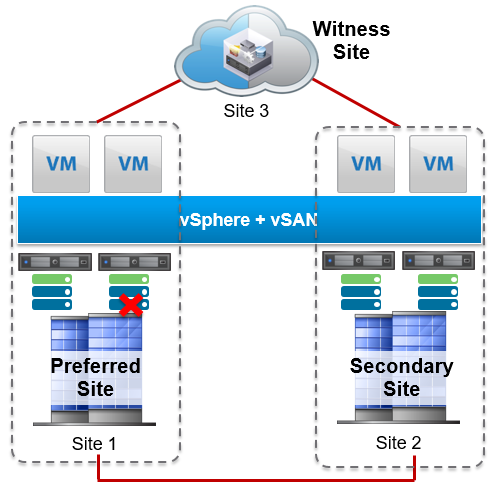
Introduced in vSAN 6.1, stretched clusters can be used in environments where disaster and downtime avoidance is a key requirement. It protects virtual machines across data centers, not just racks.
A stretched cluster extends across the following sites:
- Two active-active data sites.
- One witness site which contains the witness host to provide cluster quorum during a site failure.
A vSAN Enterprise license is needed to build a vSAN stretched cluster.
In this post, we are going to demonstrate different failure scenarios that may occur in a vSAN stretched cluster with the impact in each scenario.
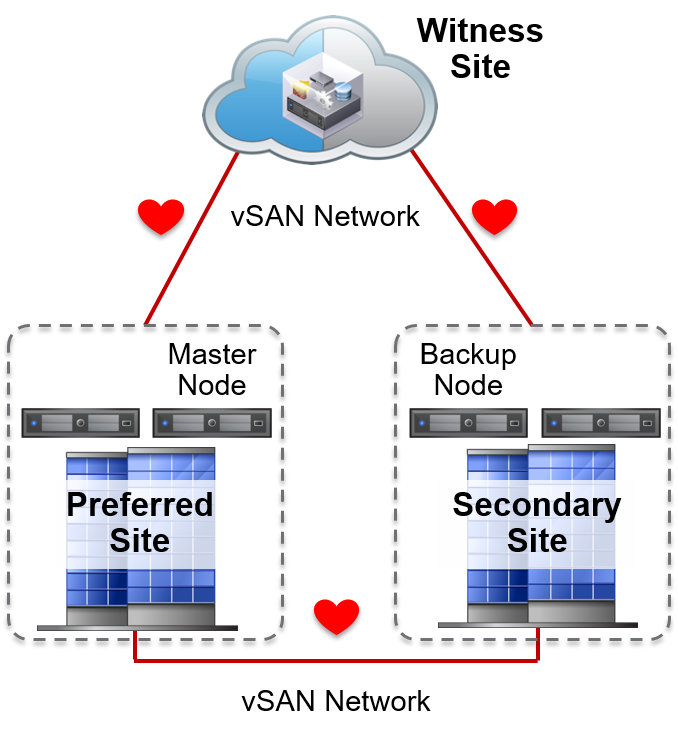
Stretched clusters use heartbeats to detect site failures. It designates a master node on the preferred site and a backup node on the secondary site to send and receive heartbeats.
Heartbeats are sent every 1sec:
- Between the master node and the backup node.
- Between the master node and the witness host.
- Between the backup node and the witness host.
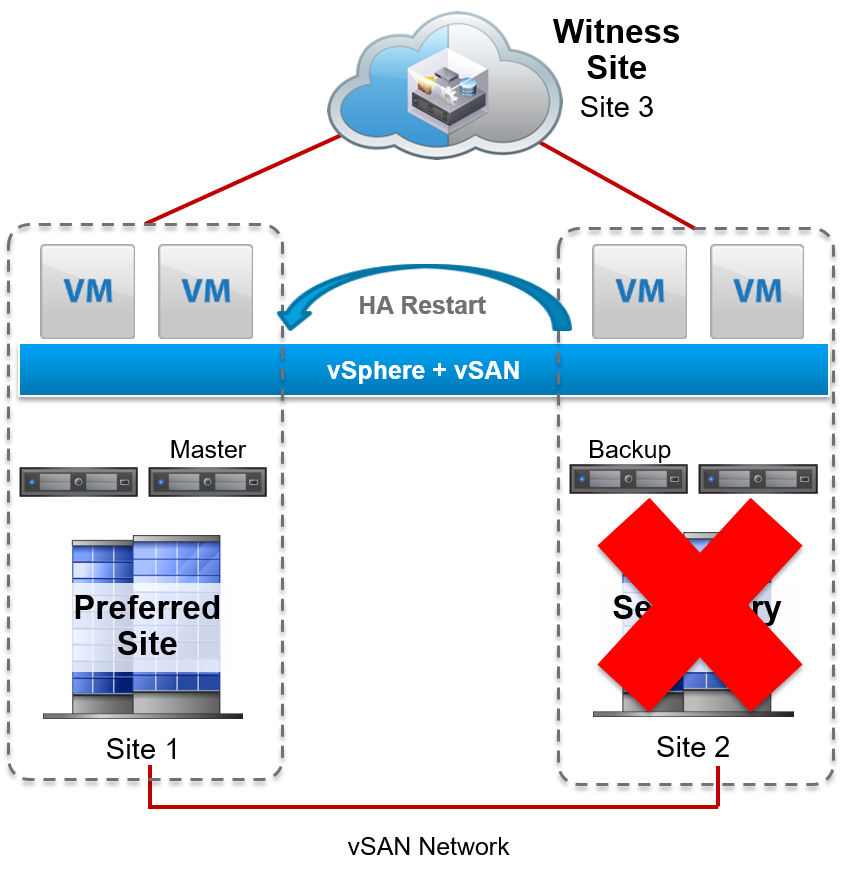
Data Site Failure
If a data site fails, vSphere HA will kick in and restart VMs running on that site on the other data site as a quorum majority (one data site + one witness site) is still available.
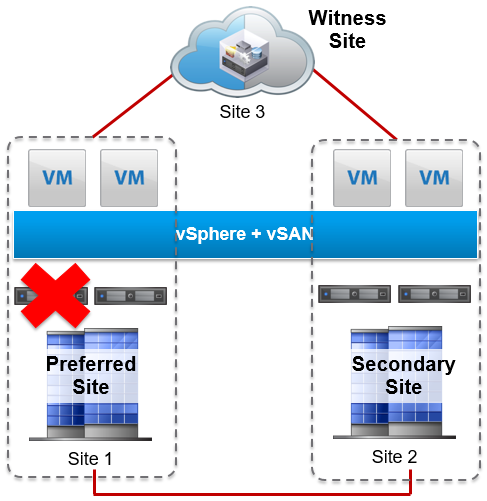
Failure of a Single Host in the Data Site
If multiple hosts exist in a data site, then vSphere HA fails over the virtual machines on the failed host to other hosts in the same site.
If the site contains a single host, then vSphere HA fails over the virtual machines to a host on the remaining data site.
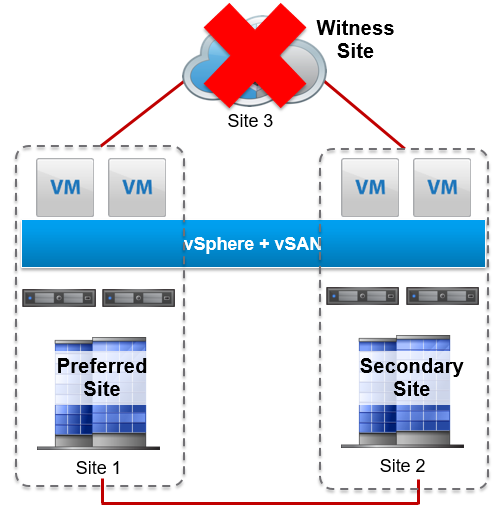
Witness Host Failure or Loss of Network Connection
If communication is lost for five consecutive heartbeats between the witness host and the data sites, then the witness has failed. Virtual machines continue to run without interruption as the two data sites continue to have a quorum.
Witness Network Failure to a Single Site
If communication is lost for five consecutive heartbeats between the witness host and one of the data sites, virtual machines continue to run without interruption as the two data sites continue to have a quorum.The witness is partitioned until communication is established.
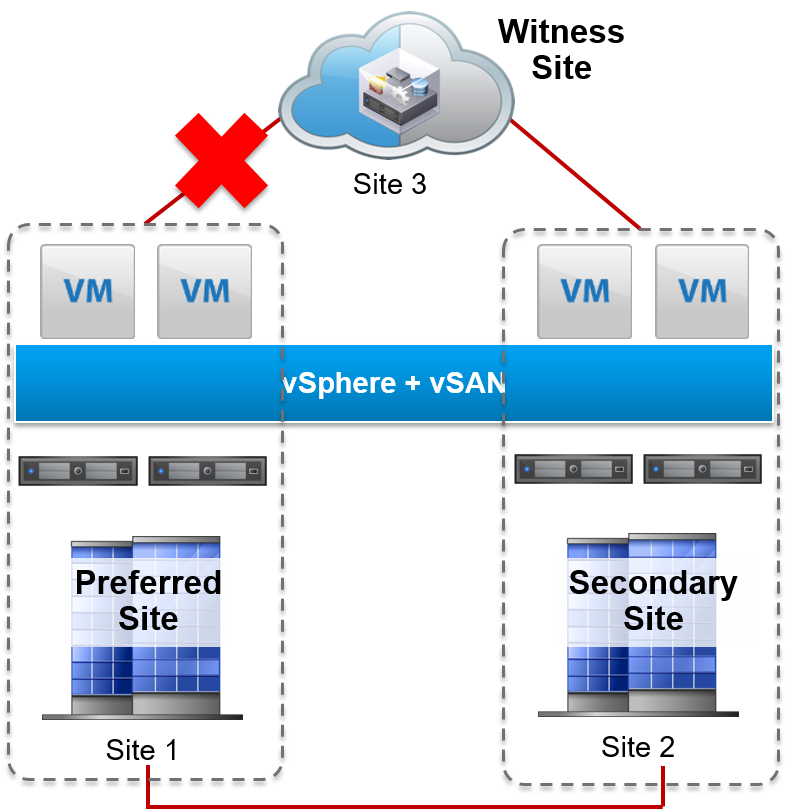
Network Failure Between Data Sites
If the network fails between the data sites, then the preferred site is selected as the surviving site. vSphere HA restarts all the virtual machines from the secondary site on the preferred site. After the network is available, DRS might move the virtual machines based on VM-to-host affinity rules.
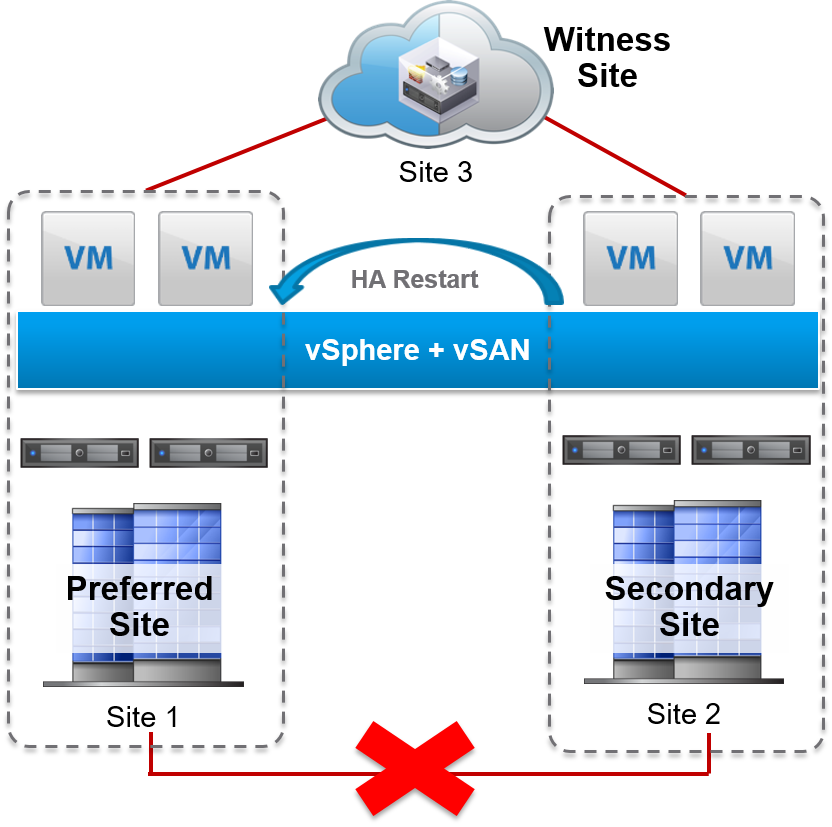
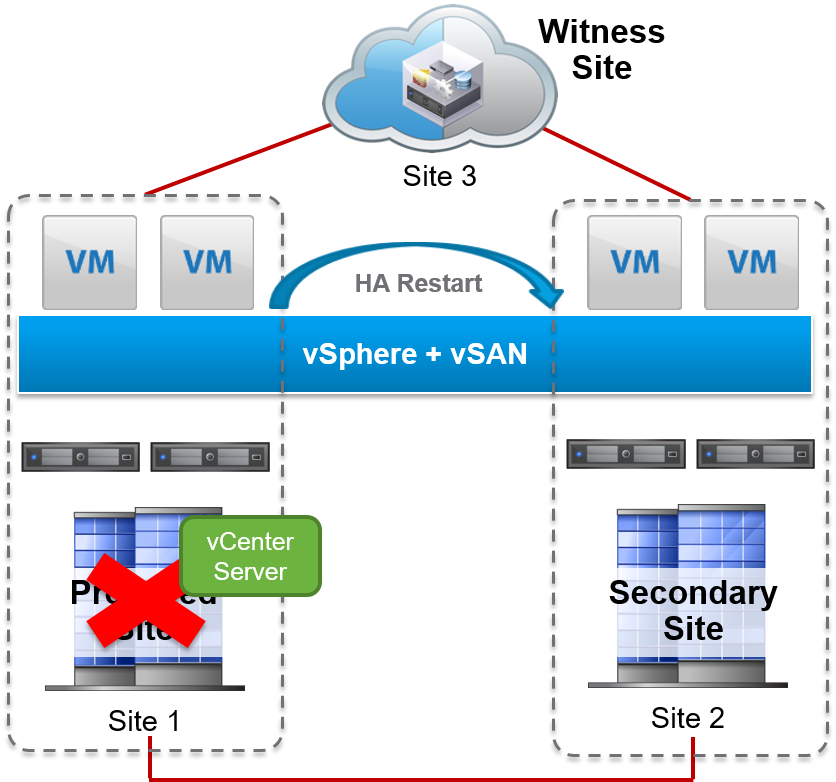
Site Failure Where vCenter Server Is Hosted
If the data site that holds vCenter Server fails, then the other site creates a quorum with the witness. vSphere HA restarts all the virtual machines from the failed site to the other site. vSphere HA is independent of the vCenter Server system.
Drive Failure
If a drive fails on one of the hosts in a data site, then the virtual machines continue to run without interruption:
- One full copy of the data is still available on the remote site.
- More than 50 percent of the components making up the object are available.
- vSAN will begin efforts to rebuild the data on the local site.
If local redundancy is configured the local components will continue to be used to satisfy reads.
Hope this post is helpful,
Mohamad Alhussein
 (3 votes, average: 5.00 out of 5)
(3 votes, average: 5.00 out of 5)
Hi – thanks a lot for the comprehensive writup!
I’m only missing one scenario: What’s happening if we have a complete outtage of the preferred site and all network connections to the witness? Will preferred site VMs be failed over to secondary and what happens to VMs running on secondary?
Best wishes,
Chris